There is certainly more to machine learning than “deep” neural networks, but significant progress is being realized by these models and are understandably very popular. I will be populating this section with different examples of neural networks that I have built – from simple 1-layer networks to recurrent, convolutional, and deep multi-layered networks.
Neural Networks
- Simple Neural Network in 9 lines of Python
- Convolutional Neural Net for MNIST digit data
- Synthetic Modernist Literature using an LSTM RNN
Simple Neural Network in 9 lines of Python
The code:
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
random.seed(1)
synaptic_weights = 2 * random.random((3, 1)) - 1
for iteration in xrange(10000):
output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights))))
synaptic_weights += dot(training_set_inputs.T, (training_set_outputs - output) * output * (1 - output))
print 1 / (1 + exp(-(dot(array([1, 0, 0]), synaptic_weights))))The output:
[0.99993704]This neural network comes from this post. It is a very simple network and doesn’t make earth-shattering predictions, but when it was first published 3 years ago, it underscored how easy it is for anyone to create and understand how neural networks operate. Also, it unintentionally illustrates how important it is to understand how design decisions might influence the choice of possible generating functions. The training and test sets are as follows:
| Input 1 | Input 2 | Input 3 | Output | |
|---|---|---|---|---|
| Example 1 | 0 | 0 | 1 | 0 |
| Example 2 | 1 | 1 | 1 | 1 |
| Example 3 | 1 | 0 | 1 | 1 |
| Example 4 | 0 | 1 | 1 | 0 |
| New situation | 1 | 0 | 0 | ? |
I printed out this truth table and took surveyed my family on what they thought the test value output would be. My 8-yr-old daughter quickly pointed out that Inputs 2 and 3 didn’t matter and that the output only depended on Input 1. The other family members weren’t as easily convinced and considered the network to have greater complexity. They saw that the training set covers both situations where Input 1 and 3 are ‘1’. So if the generating function were a logical AND gate between Inputs 1 and 3, it would explain the training data and predict a ‘0’ for the test data of [1 0 0]. However, the network’s predicted value of 0.99993704 seems to overstate the confidence in that particular generating function (Input 1). The point of the post, however, remains valid: creating a neural network is no longer the province of specialized researches. Toolkits and libraries have made them easily accessible.
Synthetic Modernist Literature using an LSTM RNN
Many years ago, I uncovered some dusty old boxes in my grandmother’s house and found some of my aunt’s old collection of philosophy, avant-garde, and beatnik books. I read through some of them but was struck (stuck) when I picked up Ulysses. I found it particularly inaccessible.
From Wikipedia: James Joyce was an Irish novelist, short story writer, and poet. He contributed to the modernist avant-garde and is regarded as one of the most influential and important authors of the 20th century. Joyce is best known for Ulysses (1922), a landmark work in which the episodes of Homer’s Odyssey are paralleled in a variety of literary styles, most famously stream of consciousness. Other well-known works are the short-story collection Dubliners (1914), and the novels A Portrait of the Artist as a Young Man (1916) and Finnegans Wake (1939). His other writings include three books of poetry, a play, his published letters and occasional journalism.
Here is a (truly) random excerpt from Ulysses:
Hurroo! Collar the leather, youngun. Roun wi the nappy. Here, Jock braw
Hielentman’s your barleybree. Lang may your lum reek and your kailpot
boil! My tipple. Merci. Here’s to us. How’s that? Leg before wicket.
Don’t stain my brandnew sitinems. Give’s a shake of peppe, you
there. Catch aholt. Caraway seed to carry away. Twig? Shrieks of
silence. Every cove to his gentry mort. Venus Pandemos. Les petites
femmes. Bold bad girl from the town of Mullingar. Tell her I was axing
at her. Hauding Sara by the wame. On the road to Malahide. Me? If she
who seduced me had left but the name. What do you want for ninepence?
Machree, macruiskeen. Smutty Moll for a mattress jig. And a pull all
together. Ex!
Now, back to neural networks since they’re easier to understand. A recurrent neural network (RNN) differs from a “normal” neural network in that it operates on sequences of data. That is, there is a relationship between successive input entries. To account for this temporal relationship, RNNs have a “memory” in the form of a hidden state vector. Each successive input is combined with this hidden state vector to produce an output while also updating the hidden state vector.
RNNs have been around since the 1980s, but like other flavors of neural nets, have become become mainstream only relatively recently. In 2015, Andrej Karpathy published a blog where he demonstrated some interesting and inspiring results using a simple variant of an RNN, called a character-level LSTM (Long Short-Term Memory) RNN. He included a small python script (<100 lines) that implemented a character-based LSTM and showed results with the script trained separately on Shakespeare, linux source code, and baby name datasets, among others. The results were really eye-opening. Despite specifying no rules on punctuation, grammar, C compiler rules, etc., the network produced astonishingly realistic output.
In this exercise, I used two of James Joyce’s novels, Ulysses and Dubliners, both freely available on gutenberg.org. Joyce produced other literary pieces, such as books of poetry, but the style of the available texts on gutenberg did not match his novels (Finnegans Wake, published in 1939, is not freely available). The issue with the poetry is that there are very few sentence endings (“.”, “!”, “?”) and the network learns to just string words together without ever ending a sentence.
I calculated the distribution of sentence lengths in the Joyce corpus and came up with this:
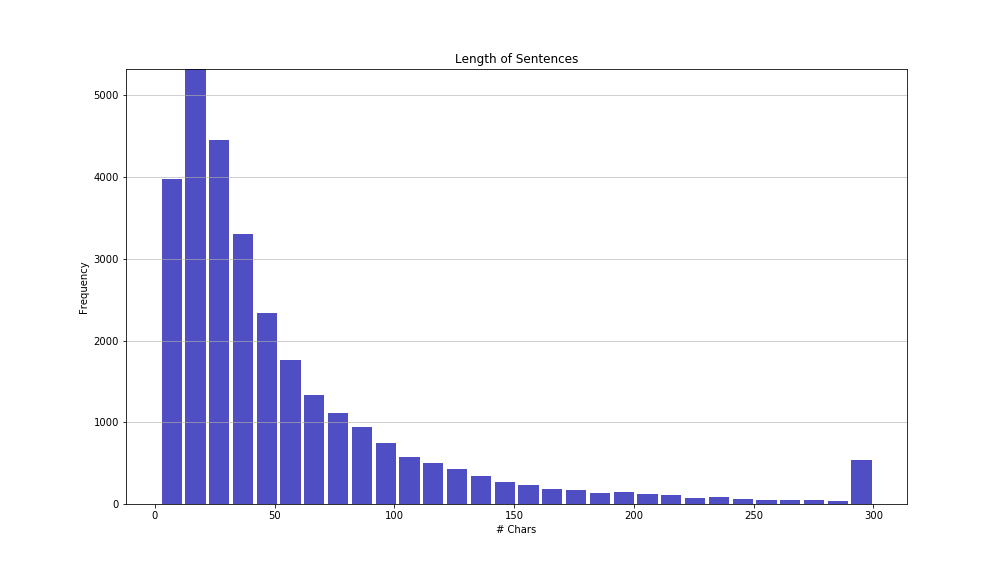
About 90% of the sentences are below 125 characters. While it would be preferable to train sentences as long as possible, the longer the sentence, the more hidden nodes needed to learn the sentence structure. And the more parameters in a model, the more complex it is, and the longer the training time (and more difficult to optimize). So, I picked a sentence (text fragment) length of size 100 as this seemed a good compromise – and still covers 86% of Joyce’s sentences (below length 100).
The other tuning parameters in an LSTM are the number of stacked levels and the number of hidden nodes in each stacked level. For the stacked levels – this is usually between 1 and 3. ‘3’ is preferred in order to capture some of the more separated characters (and words), since higher complexity can deliver better performance (assuming the model is optimized properly). Since I am training my CNNs using a CPU rather than a GPU, the training times are much higher, so I had to go with a single LSTM layer. I used 128 hidden nodes in the LSTM layer as it’s about the most hidden nodes I can use and still have a reasonable training time (on the order of a day).
Here is the loss plotted by epoch (an single, entire run through the training data):
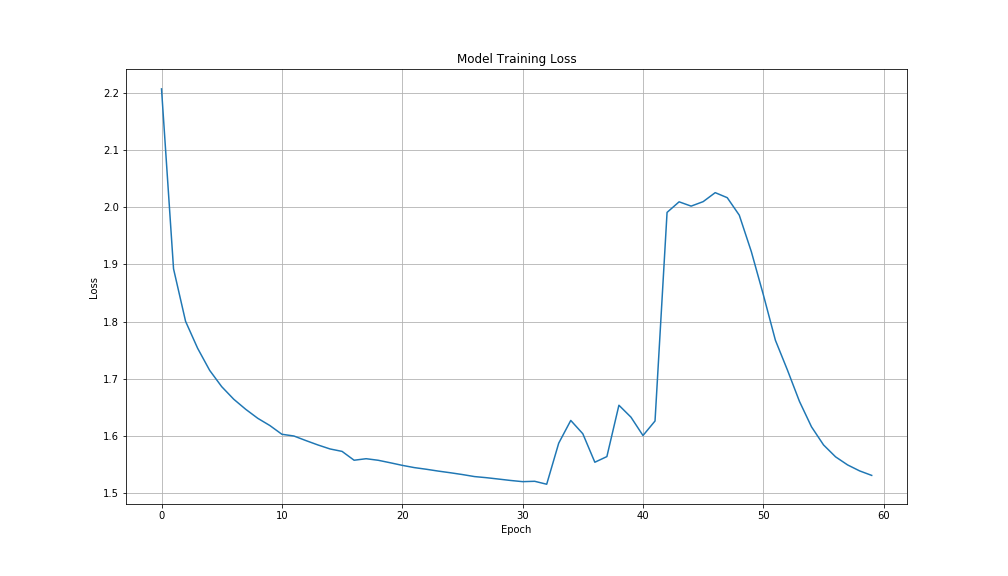
At the end of each epoch, a checkpoint was made of the model, allowing for predictions to be made, given an input seed. After the first epoch, the model produced the following (the seed is in bold).
Epoch 1:
No, she couldn’t say. But it would be in the paper. O, she need not trouble. No trouble. She waved and his for she bating his cond sere parsed and boon and she the bece and his bell of the said said the of to the shand the singer the stupper tire rook he sore dinged in the sore and the sind of she cont of the charter some the said the she can and bring be the had beting the said the priss said him and she read the courd state of the har she she con the porded the rame of the sand the the all spe…
In this first model, there are both recognizable words and nonsense words. But the words are short and simple and there is little in the way of punctuation.
Epoch 2:
No, she couldn’t say. But it would be in the paper. O, she need not trouble. No trouble. She waved a conted up a stilling at the conferical on the courted his his a seeper him to he was in the cause of she was a comp the stare to the cropping they was of the what the conder a bentor of sing and him a she come could he was a gon’t he asked sire and better he shill on the cassing it the dook and to the could in the down the sices and bent in the dide and a ba see in the couraricled and he was a ju…
By the 2nd epoch, the words are getting more complex, but many are still largely imaginary. Also, no semblance yet of sentence structure – just words strung together.
Epoch 10:
No, she couldn’t say. But it would be in the paper. O, she need not trouble. No trouble. She waved and the place of the corners of are the street of a mate she had a proper and the chare the gentleman compantion of the coller and the recent and the menter the pointing to a strangering and the postage the matter. But a brong and characted by a strange in her had eater of the coming the past the corner of any the lower scrump and he said that the end face he see and the object of the such and said…
By the 10th epoch, there are fewer imaginary words and pockets of word sequences in each sentence are starting to make more sense (“place of the corners”, “street of a mate she had a proper”, etc.), whereas in the first few epochs, it was just random words strung together.
Epoch 20:
No, she couldn’t say. But it would be in the paper. O, she need not trouble. No trouble. She waved and a burse which he had enoughless and stander him. He was a polity of the staid. He called him.
—And she was stocking all the suppose of the son her corner and he had a sight of that his hand of the corner of the last after the same beside him and but the wife but the more to her standing this plump and the brow second him and he was a second of the same on the shout of his lawsed to the c…
By epoch 20, there is not only punctuation and fewer fantasy words, but the sentences are starting to look a little more plausible.
Epoch 31:
No, she couldn’t say. But it would be in the paper. O, she need not trouble. No trouble. She waved at the eyes and the Chandler and the man was the band and the words of the case and the face the and which the land and with the constand and he said.
—That’s a country like a man. He was a woman and the last boy, grand at the she as a few man and the contracted behind a grandlies of the some of the corner, the card in the part.
—The house in the street to see it. Mr Bloom said to medically a…
By epoch 31, there is more advanced sentence structure and maybe even some thought-provoking phrasing. I really do believe that a layered LSTM could get much closer to Joyce’s writings, so it’s a little disappointing to have to abandon ship right now, but that’s as far as I can go with my GPU. The takeaway from this exercise is not necessarily the final output but rather the idea of how well LSTMs are able to mimic the source corpus without having any formal rules defined for words, grammar, and sentence structure. Nowhere in the code are any rules of what words are legitimate and what words are not. Nor is there any defined rule on capitalizing the first letter following the end of the previous sentence. There is no explicit rule that the network cannot repeat words over and over, yet the network has learned all of these things.
Here, by the way, is the original excerpt from Ulysses:
No, she couldn’t say. But it would be in the paper. O, she need not trouble. No trouble. She waved about her outspread Independent, searching, the lord lieutenant, her pinnacles of hair slowmoving, lord lieuten. Too much trouble, first gentleman said. O, not in the least. Way he looked that. Lord lieutenant. Gold by bronze heard iron steel.
—………… my ardent soul
I care not foror the morrow.
In liver gravy Bloom mashed mashed potatoes. Love and War someone is. Ben Dollard’s famous. Night he ran round to us to borrow a dress suit for that concert. Trousers tight as a drum on him. Musical porkers. Molly did laugh when he went out. Threw herself back across the bed, screaming, kicking. With all his belongings on show. O saints above, I’m drenched! O, the women in the front row! O, I never laughed so many! Well, of course that’s what gives him the base barreltone. For instance eunuchs. Wonder who’s playing. Nice touch. Must be Cowley. Musical. Knows whatever note you play. Bad breath he has, poor chap. Stopped.
Here is the code:
from __future__ import print_function
from keras.callbacks import LambdaCallback, ModelCheckpoint, TensorBoard, CSVLogger
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers import LSTM
from keras.optimizers import Nadam
import numpy as np
import random
import sys
text = ''
whole_line_list = []
with open('JamesJoyce.txt', encoding='utf-8' ) as f:
whole_line_list = f.readlines()
line_list = []
for line in whole_line_list:
if not line == "\n":
line_list.append( line.strip() )
else:
line_list.append( "\n\n" )
text = " ".join( line_list )
print('corpus length:', len(text))
chars = sorted(list(set(text)))
print('total chars:', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
# cut the text in semi-redundant sequences of maxlen characters
maxlen = 100 # about the max length of a word but need periods(!)
step = 3
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('nb sequences:', len(sentences))
print('Vectorization...')
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
# build the model: a single LSTM
print('Build model...')
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars)), return_sequences=False))
model.add(Dense(len(chars)))
model.add(Activation('softmax'))
#optimizer = RMSprop(lr=0.01)
optimizer = Nadam()
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
model.summary()
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
def on_epoch_end(epoch, logs):
# Function invoked at end of each epoch. Prints generated text.
print()
print('----- Generating text after Epoch: %d' % epoch)
start_index = random.randint(0, len(text) - maxlen - 1)
for diversity in [0.2, 0.5, 1.0, 1.2]:
print('----- diversity:', diversity)
generated = ''
sentence = text[start_index: start_index + maxlen]
generated += sentence
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
for i in range(400):
x_pred = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
print()
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
tensorboard = TensorBoard( log_dir="./logs" )
csv_logger = CSVLogger( "./logs/stacked-64-32-32-training.log.csv" )
filepath = './checkpoints/stacked-64-32-32-{epoch:02d}-{loss:0.2f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=False, mode='max' )
model.fit(x, y,
batch_size=128,
epochs=60,
callbacks=[print_callback,checkpoint,csv_logger,tensorboard])
Much easier to read than Ulysses, IMO.